Slack Responder Guide
Prerequisites
For this guide, we assume:
- Your basic integrations (Jira, Zoom, Slack, etc.) have already been set up by an admin
- You have a user account on FireHydrant within your Organization*
If the above is not met, we recommend reaching out to your FireHydrant Owners to invite you to the organization and to set up the integrations required. Reading the introduction will give you an idea of the FireHydrant platform's many moving parts.
NoteIf your organization exists on FireHydrant already, do not register for an account directly on FireHydrant's website - this will create a new, separate organization. Instead, ask an admin from your org to invite you/provision an SSO seat for the existing organization.
Basic FireHydrant concepts
- Incident: Any declared situation. Can range in severity from
UNSET(unknown severity) toSEV1or whatever you customize. Each incident has its own home page and timeline. - Milestone: The current status of an incident. As you mitigate, you will want to keep this up-to-date, and FireHydrant will automatically log the timestamps of these transitions to generate our Analytics.
- Runbook: FireHydrant's automation engine. Traditionally, "runbooks" describe sets of instructions and steps for responders to execute, but on FireHydrant, these steps will execute automatically.
- Service Catalog: FireHydrant's catalog for your system's components. It helps tie together teams, users, and the components they own, making it easy to pull in the right people for the right things.
- Retrospective: A review of an incident. FireHydrant's Retrospectives contextualize and gather all incident information for you to make your reviews focused and productive.
For a deeper view of all parts of FireHydrant and the incident lifecycle, visit the Incidents section of the documentation on the left.
Incident Response
With the above concepts covered, let's dive into conducting incidents.
FireHydrant supports driving incidents end-to-end from both Slack and the user interface. If Slack is ever down or having a moment, you can still count on FireHydrant to support your incident management. Visit the Web UI Responder Guide to see how to conduct incidents via the web UI.
This guide covers most of the available actions you can take in an incident and links out to documentation pages providing additional detail.
NoteSee the complete list of Slack Commands.
Starting incidents
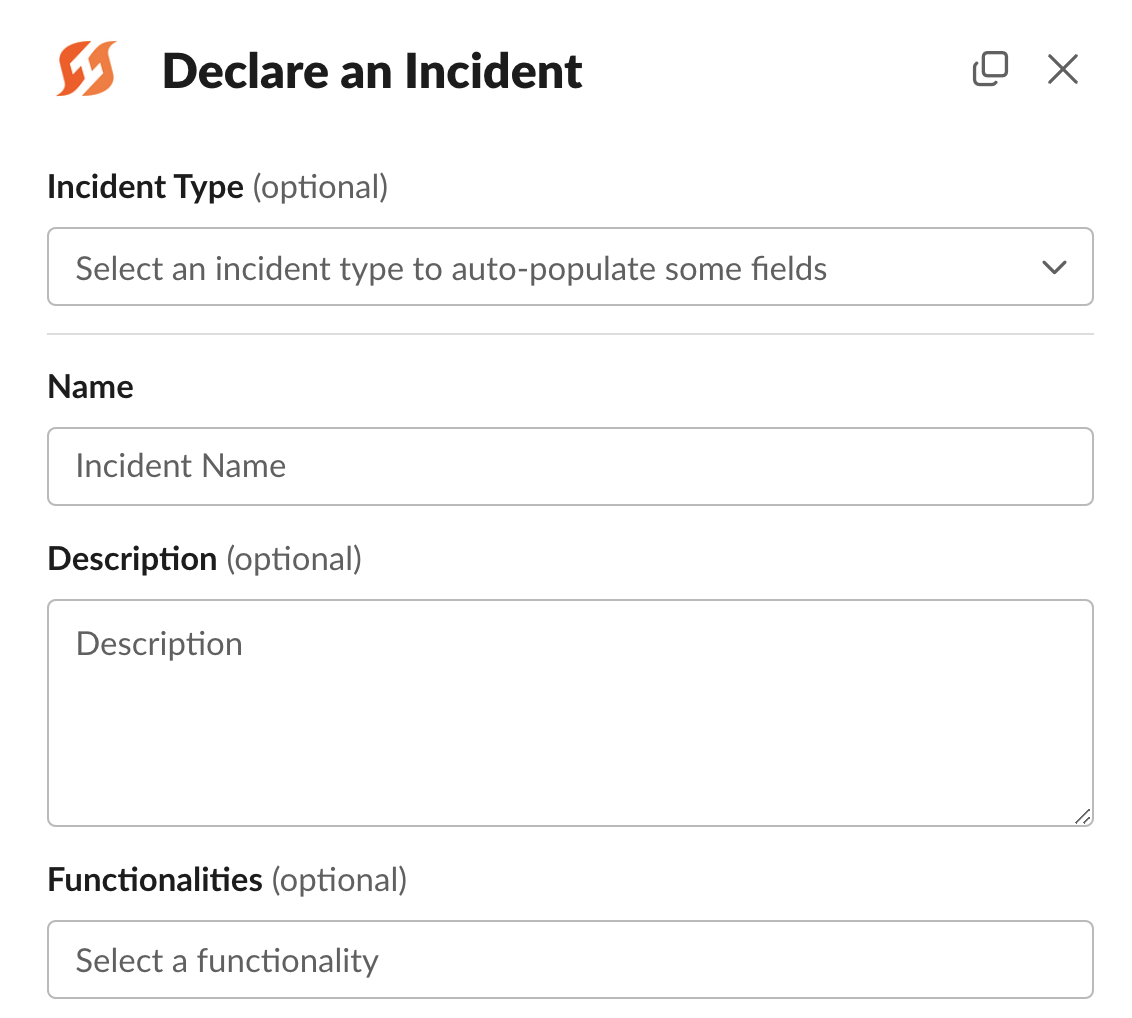
Declare Incident modal in Slack
/fh new [title]
/firehydrant new [title] # alias
/incident new [title] # alias
/new # shortcut command, does not accept argumentsThis opens a dialog box asking for additional information to kick off the incident. This form can be customized by Owners and Members of your organization.
Anyone can declare an incident from Slack without needing a FireHydrant license.
Additional Resources
Assigning roles and teams
Assigning roles and teams will automatically pull users into the incident Slack channel. It's also helpful for keeping a record of who was responding to the incident.
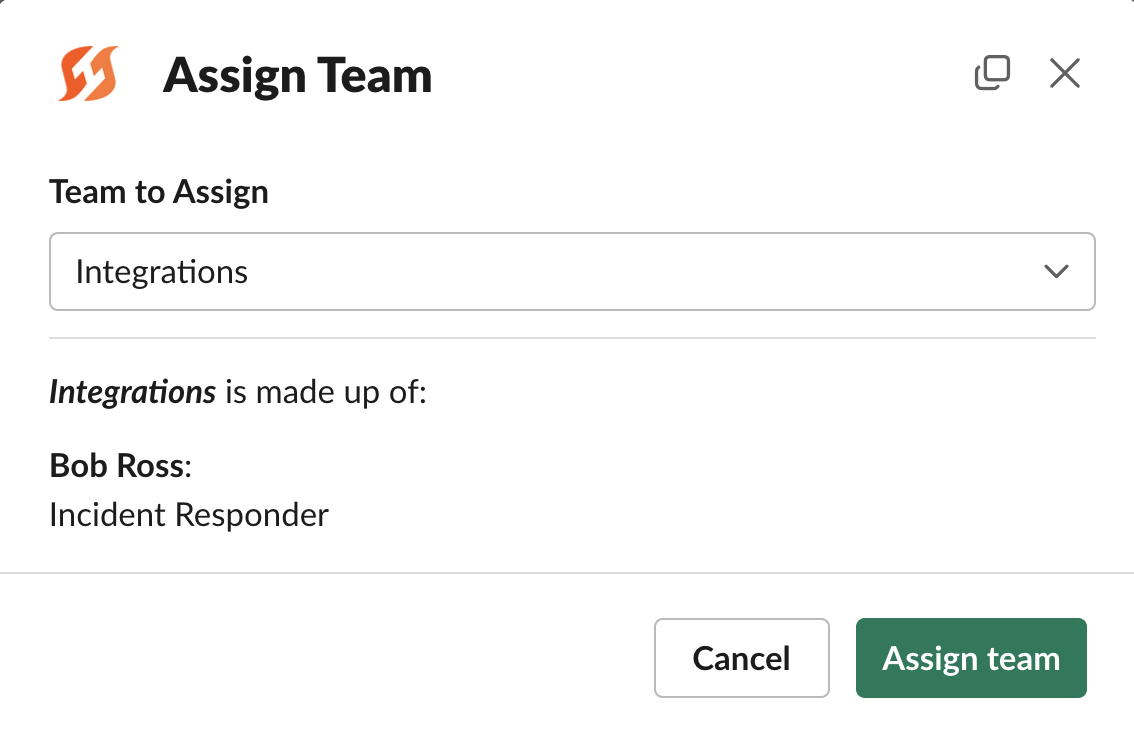
Assigning teams via Slack
You can assign roles and teams with the following Slack command:
/fh assign role # For individuals
/fh assign team # For teamsAdditional resources
Managing tasks
Task management can help streamline the response and ensure responders know what they need to do. You may create and assign tasks ad-hoc or predefine lists of tasks to assign during incidents.
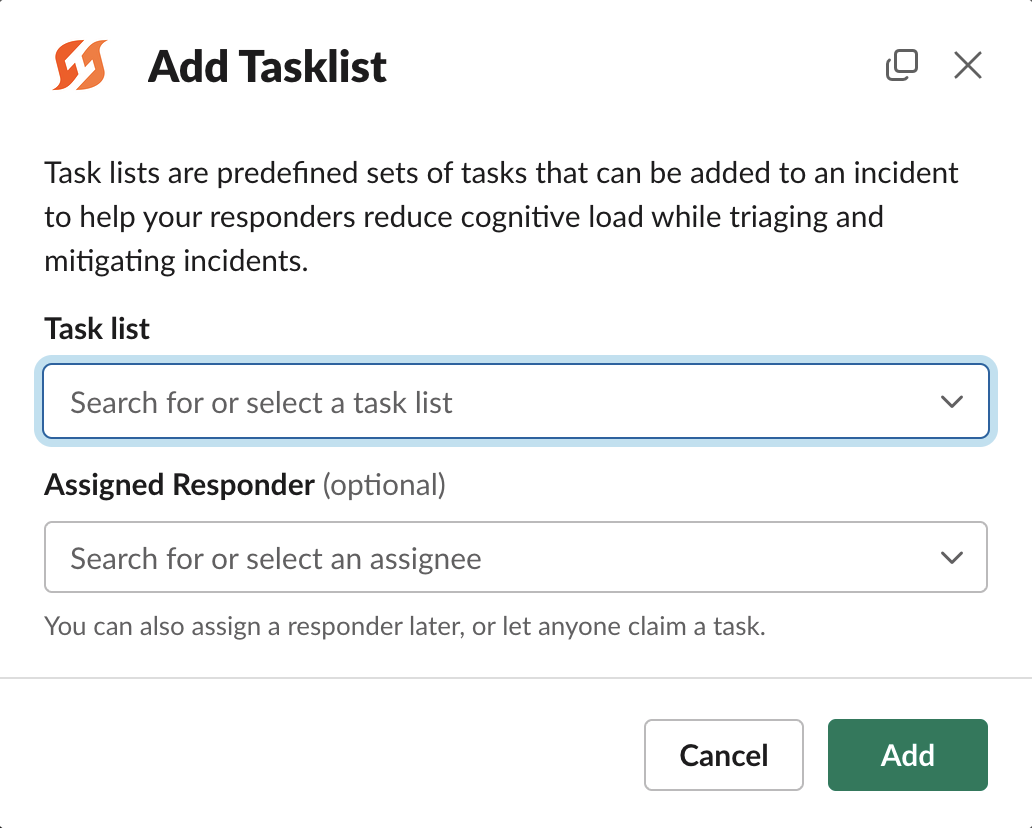
Add Tasklist modal in Slack
In Slack, you can use the following commands:
/fh add task # Create ad-hoc task and optionally assign
/fh add task-list # Assign a predefined list of tasks
/fh tasks [unassigned | @user | all] # See unassigned/user's/all tasksYou can also create a task by reacting to a Slack message with an emoji. The default is :ballot_box_with_check:, but this can be customized in your Slack settings.
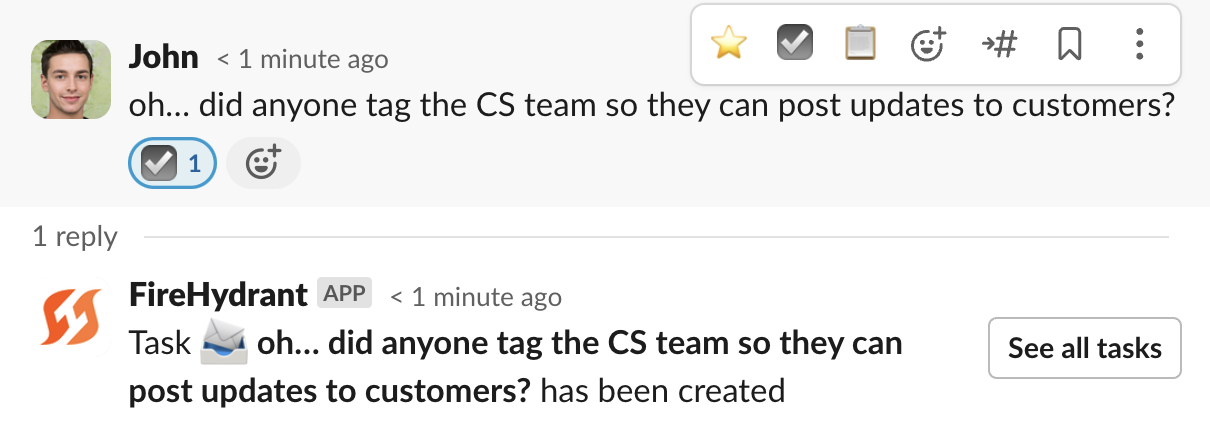
Creating Tasks from emoji reaction to a message
Additional resources
Editing incident details
On FireHydrant, we distinguish between editing vs. posting updates on an incident. An Edit is a modification to incident details, such as the severity, name, description, or any other fields.
/fh edit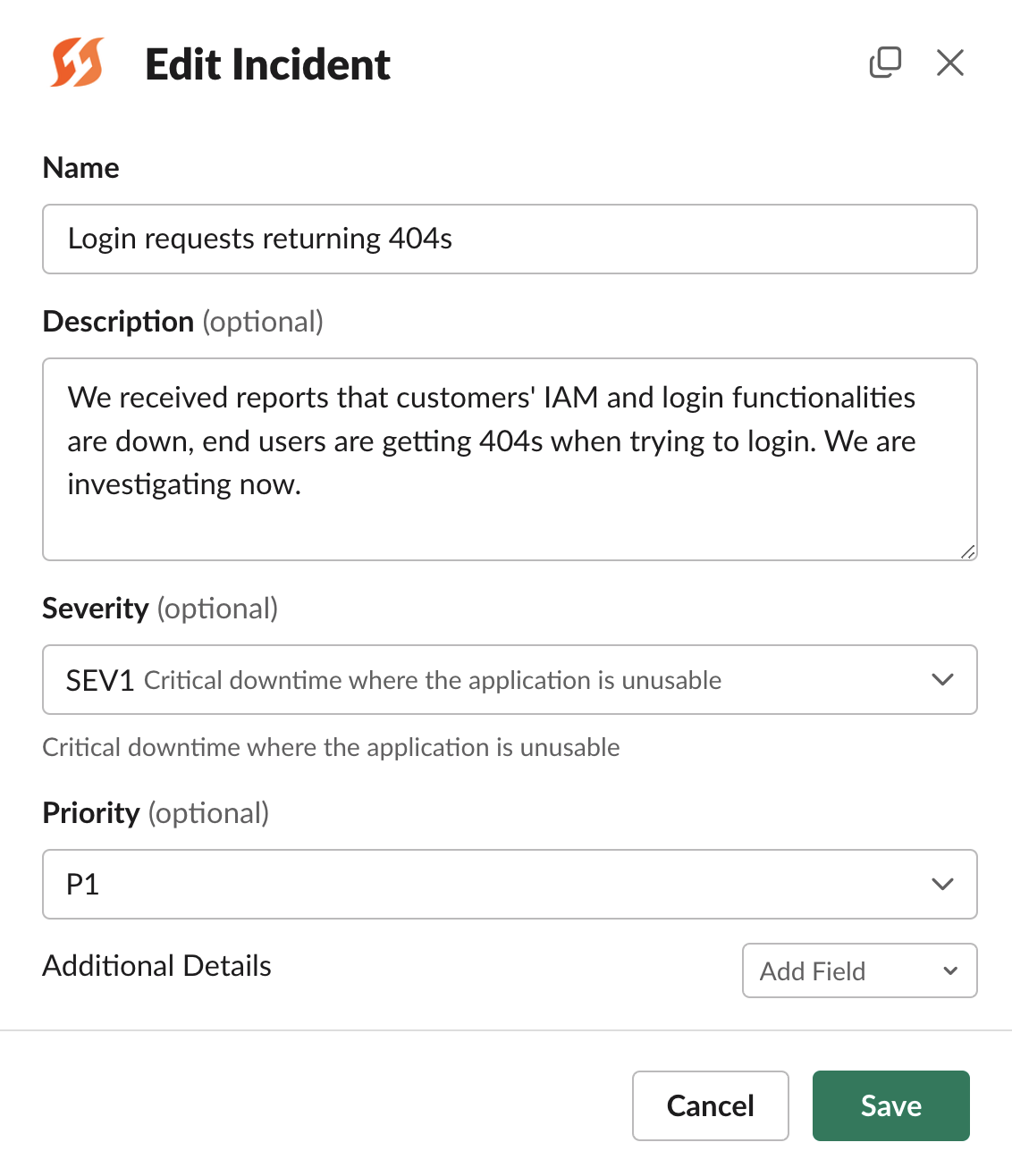
Edit modal in Slack
Posting an update
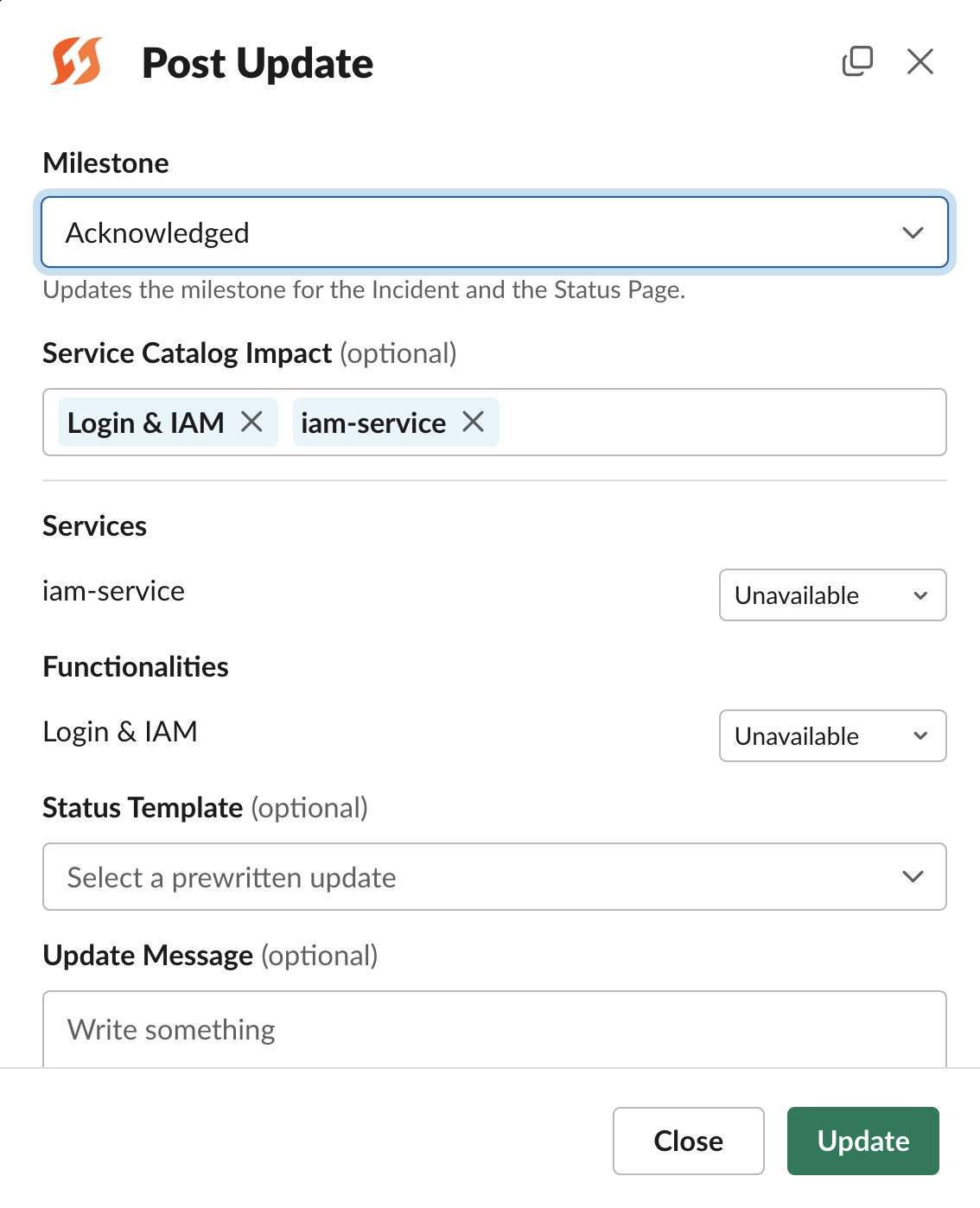
Slack Update modal
/fh update
/fh post # (alias)
/fh add note # (alias)An Update is a more formal status message from a responder on the overall progress of an incident. These updates may additionally be sent to status pages so other stakeholders are in the loop. This also typically includes a change to the Milestone as well as changes to impacted components.
Starring important events
You can flag specific messages or timeline events as important. We call these "Starred events," and they are shown first in the Retrospective and exported as part of the timeline to PDF, Google Docs, and Confluence.
In Slack, the default configured emoji is ⭐, but you can customize this to be any emoji you'd like. When you "star" an item, FireHydrant bot will respond with a 🔥 emoji to acknowledge that it's flagged.
Items starred from Slack will automatically be starred in the Command Center as well.

Starring items from Slack
Additional Resources
Viewing service info & paging
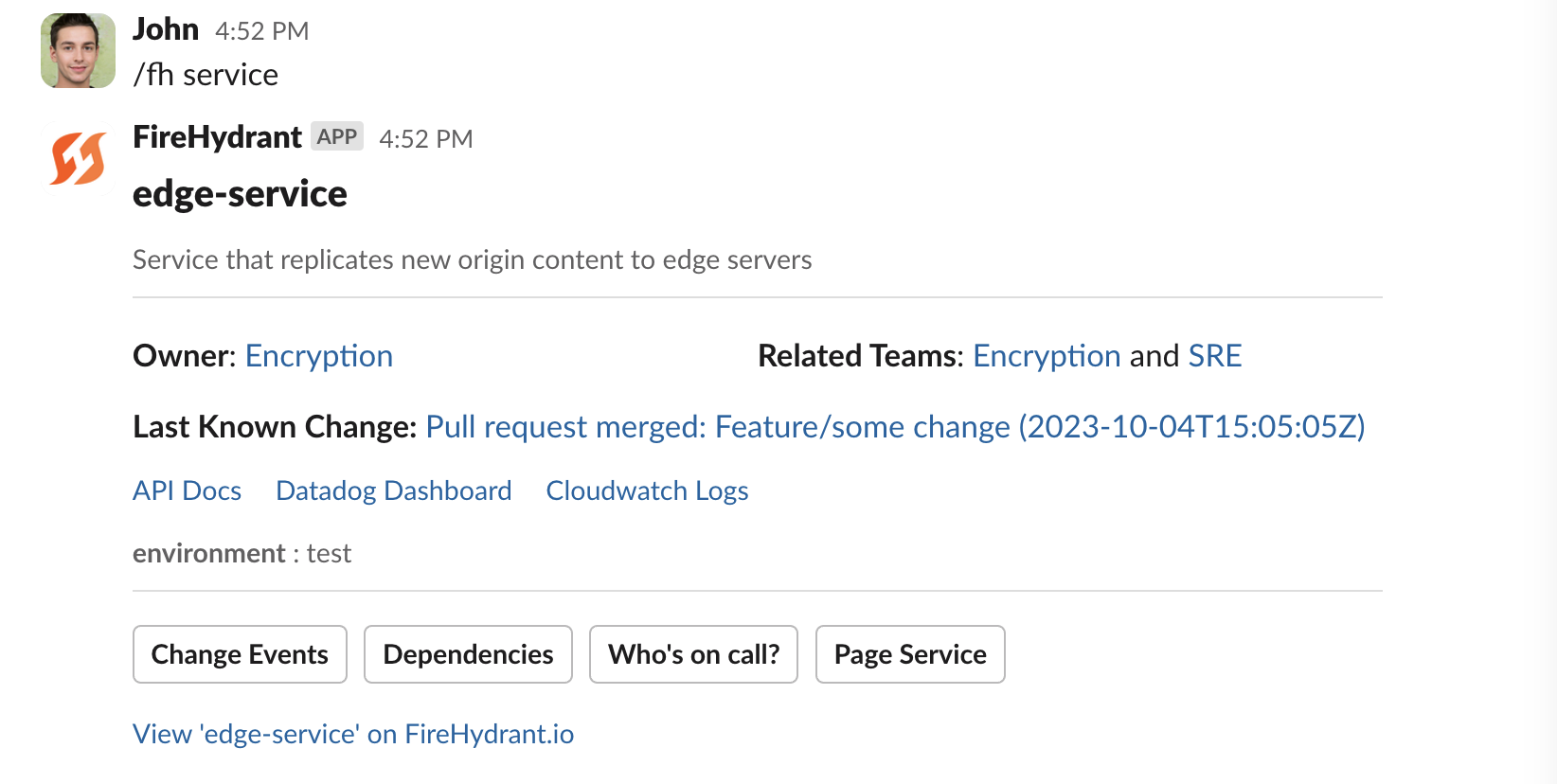
Looking up service info from Slack
/fh service [service-slug] # Look up service info
/fh page # Page out to more responders (requires at least one alerting provider configured)
/fh page service [slug] # Page responders for specific service (requires linked service)
/fh page functionality [slug] # Page responders for specific functionality (requires linked functionality)FireHydrant's integrations and Service Catalog allow for looking up service info and paging out to more responders.
Note:
/fh pageis a generic paging form that allows paging external escalation policies, services, teams, or individuals depending on the alerting provider used./fh page [service | functionality][slug]is to page attached on-call schedules of specific components, and requires linking external services.
Additional Resources
Create follow-ups
While Tasks are ephemeral items to handle during an incident, Follow-Ups are action items that should be prioritized for work later. When creating Follow-Ups, you have the additional capability to select an external ticketing project, and this will create a corresponding ticket in a 3rd-party tool (like Jira).
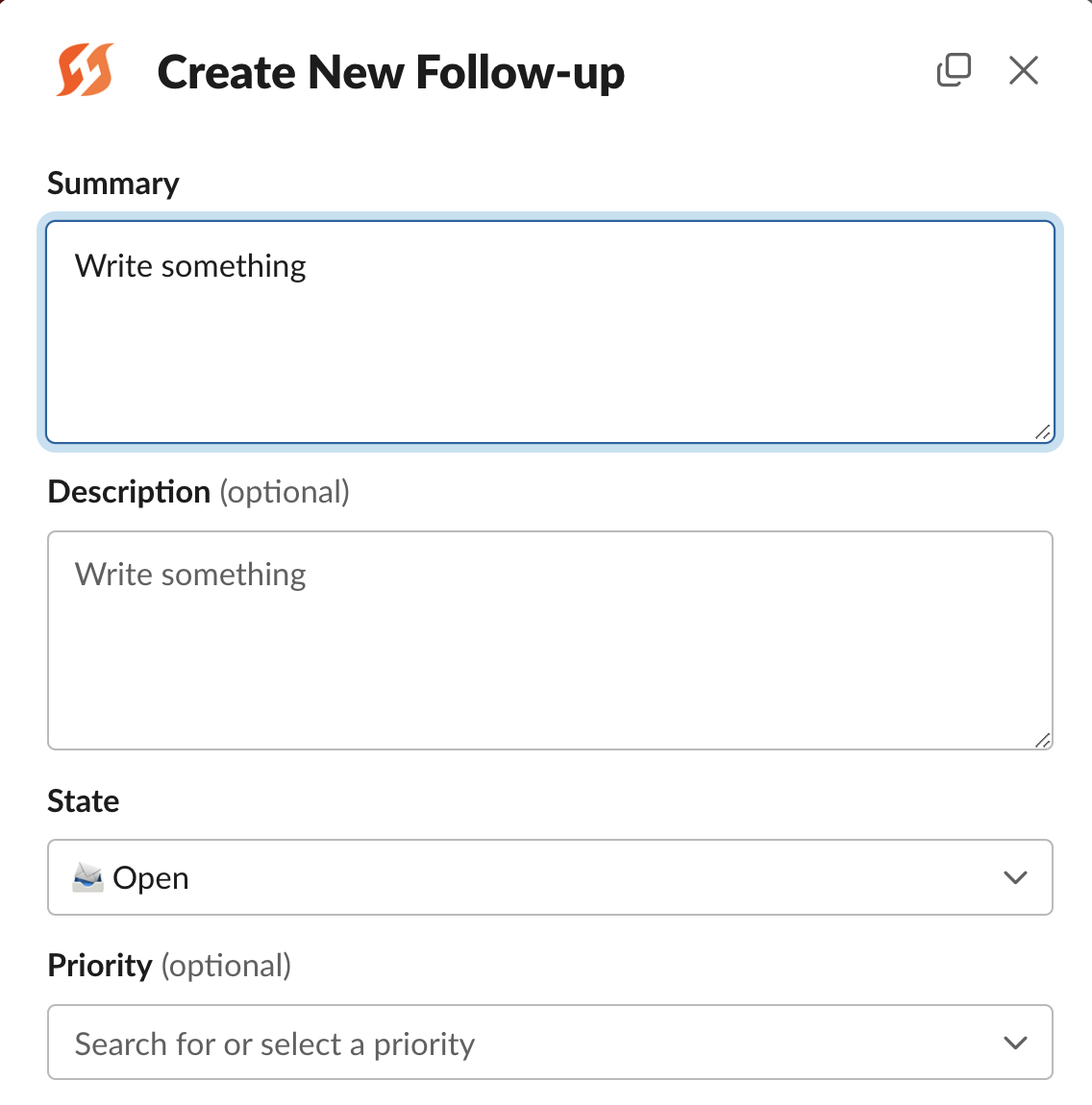
Follow-up modal in Slack
/fh add follow-up [title] # Create a Follow-up
/fh action-items # Show all open Tasks and Follow-ups. Will be deprecated soonAdditional Resources
Resolving the incident
Typically, users will first transition an incident to the Mitigated Milestone and observe the situation for a while to ensure things are stable. Once engineers have confirmed or feel confident things are fully resolved, they may close the incident on FireHydrant.
Note:Resolving an incident will halt all current repeating Runbook steps, resolve the incident on any attached status pages, and update all Slack notify messages to reflect the new state.
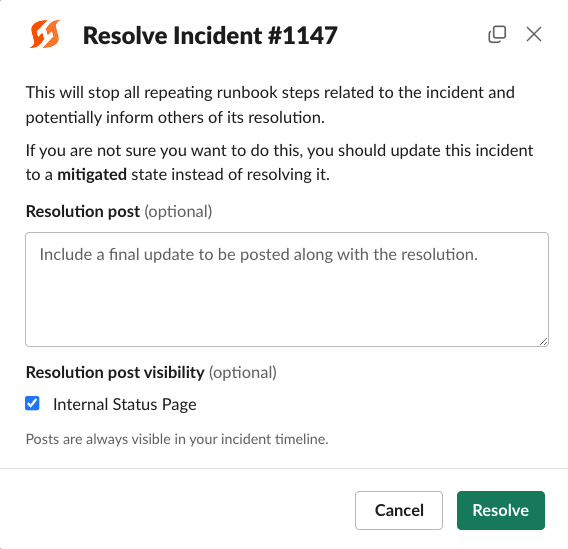
Resolve incident modal in Slack
/fh resolveAdditional Resources
Running a retrospective
A retrospective is your team's opportunity to learn from the incident. Although you can initiate the Retrospective from Slack, you'll need to head over to the FireHydrant Web UI to fully conduct this final stage of the incident.
Starting the retro
/fh start retro # Transitions incident to "Retrospectived Started" milestone
NoteStarting the retro from Slack will transition the milestone to Retrospective Started, which also resolves the incident. You can start the retro from any other state/milestone.
Conducting the retro
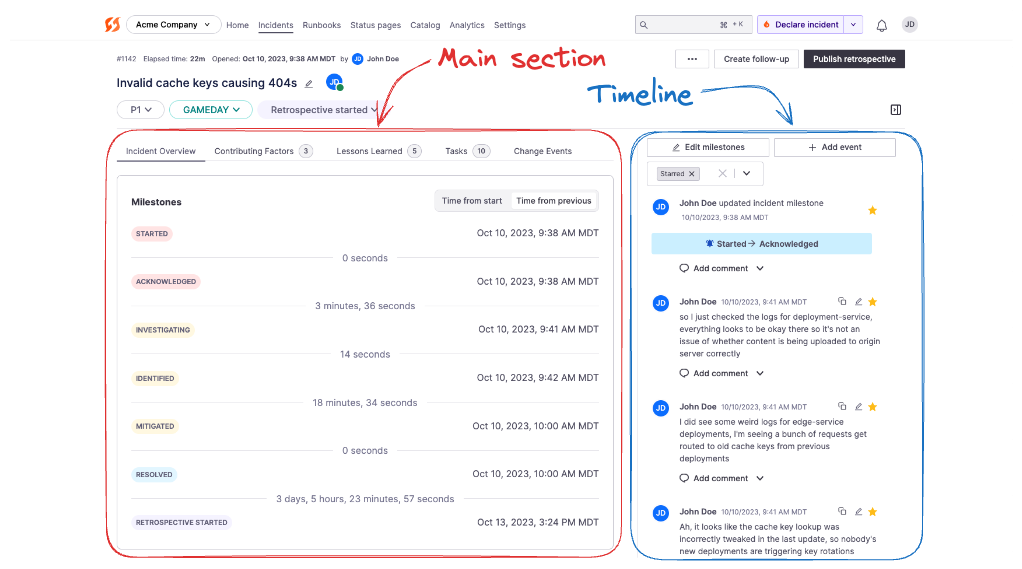
Incident Retrospective
The Retrospective, like the Command Center, has two sections: the main section and the timeline. The timeline is to the right and shows Starred Events by default. You can adjust the filters to show other events.
The main section contains the core content of the retrospective, separated into multiple tabs. You can work your way through all of the details and tabs one by one.
- Incident Overview - Provides a summary of key information like milestones, description, customer impact, impacted components, responders, and more.
- Contributing Factors - These are the items that are seen as having led to the incident, or the "causes". Many of our customers do their "5 Whys" analysis here and also note down any other factors that could have contributed to starting this incident.
- Lessons Learned - These are the review questions. FireHydrant ships with default questions, but these can be customized according to your organization's needs.
- Tasks - This is the same Tasks tab shown in the Command Center. Here, you can review all of the open/closed Tasks as well as Follow-Ups.
- Change Events - FireHydrant can ingest change events in your repositories or infrastructure and automatically associate them to incidents based on which components were impacted. You can then mark them as the cause of an incident or dismiss them.
Once you've filled out the Retrospective, click Show export at the top right of the Retrospective, which will transition the incident to the final milestone: Retrospective Completed. This will also generate a PDF report of the retrospective, and if your organization has these Runbook steps configured, will also export the report to Google Docs and Confluence.
Additional Resources
Reviewing Analytics
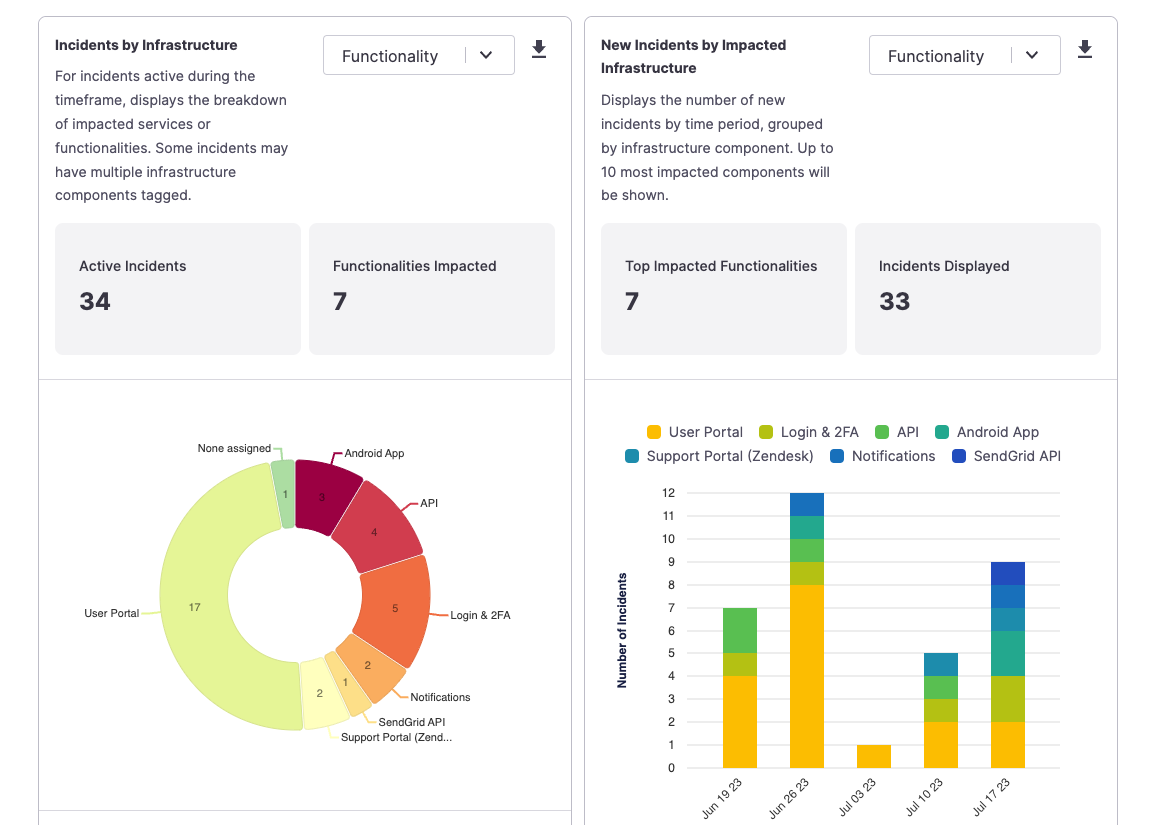
Example Analytics graphs
Once you've completed the retrospective, head over to the analytics section of the FireHydrant UI to see what types of metrics we track. All of the graphs can be exported to CSV or PNG formats for easy insertion into a report, and all data is accessible via API as well.
Additional Resources
Wrapping Up & Next Steps
Now that you've seen how to conduct incidents in Slack, check out the Web UI Responder Guide to see how you can continue to reliably manage your incidents even if your chat app is not available
These guides only cover the basics of conducting incidents on FireHydrant. For more guides, see the docs sections on the left:
- Incidents section has in-depth guides for every piece of incident management and platform configuration
- Runbooks section contains details about Runbooks and how to automate and tailor your processes
- Analytics covers our Analytics capabilities in-depth
- Catalog contains documentation on our Catalog and how to set up and use it for more effective incident management
- Status Pages discusses FireHydrant's proprietary status pages. You can also integration FireHydrant with Atlassian Statuspage
- Integrations section covers all of the available integrations FireHydrant has
- Administration covers general account, user, and team configurations
- Reference contains quick-reference documentation that users may find themselves visiting time to time again.
If you have any questions or concerns, reach out to the Support team or your FireHydrant Account team if you're working with one.
Updated 3 months ago