Running a Fire Drill

Fire drills, also called "gamedays," help align your incident response team and prepare them for real incidents by working through a mock incident scenario.
We recommend running fire drills regularly to refresh your responders on FireHydrant functionality, review your processes for gaps, and train on any new changes made to either your processes or FireHydrant's product, as we regularly release new capabilities or revamp existing ones.
Tips for running fire drills
Create a low-stress environment
If you're testing alone or with a small group, ensure the rest of your organization knows it's just a mock incident. If doing a larger team-based drill, schedule it on the calendar, but communicate clearly that this is only a practice.
Most importantly, throughout the mock incident, don't worry about perfection. Chances are you'll learn things from your first fire drill and make some changes to your runbook(s).
Set expectations and choose a scenario
Although it's meant to be stress-free, not having an agenda can lead to wasted time. It's best to have a plan and choose a scenario you will play out.
We recommend using a recent incident your team handled. Having a real, previously experienced scenario gives participants a clear image and comparison of how things go this time vs. how they went before.
Focus on process and workflows, not minutiae
As stated above, the goals of a fire drill are to improve familiarity with FireHydrant and overall processes and identify gaps. Ensure your team members aren't hung up on extraneous details or dive too far into the weeds on anything (e.g., "well ackshually, that incident was caused by clock skew in a distributed cluster, and after searching through 10 GB of logs...").
Encourage participation
The point of fire drills is to practice and improve. There are no wrong answers or bad questions, and (hopefully) nothing important is breaking! Reliability is a company-wide metric, and every responder's feedback is important to consider.l
Recommended fire drill steps
These are the recommended steps for working through your fire drill/gameday incident. You are welcome to take these and modify them; they are provided as reasonable defaults based on numerous past customers we've worked with.
Tip : Bookmark our Slack Commands cheat sheet!
1. Start the incident
/fh newYou can do this in several ways, depending on how you've configured things. The simplest way would be to enter /fh new into Slack. Use the GAMEDAY severity to signify this incident is a fire drill.
Teams feeling fancier and more confident can configure Alert Routing and potentially trigger a FireHydrant incident from an external source like PagerDuty.
After the incident starts, your automation in Runbooks should have kicked off. For many users, this involves the creation of an incident channel, a meeting bridge, and various other things like assigning task lists, teams, and more.
2. Take action in the incident
The team(s) or individual(s) assigned should respond to the incident. From here, workflows can diverge greatly depending on organization processes and needs, so we recommend having the Responder Guide open as you work through the incident to refresh on any commands or capabilities.
Note:Remember to Star events/mark them as important as you go through your mock incident!
3. Resolve the incident
/fh resolveOnce you've reviewed your mock scenario and the incident is deemed "resolved," resolve it in FireHydrant. This will officially close the incident and mark all impacted components as "Operational" again.
4. Run the retrospective
Now that the incident is resolved, it's time to run a retrospective! For the most part, you can run your incidents entirely out of Slack. However, retrospectives need to be done inside the FireHydrant UI. We recommend:
- Reviewing the timeline of starred/important events
- Recapping the description, customer impact, impacted components, and involved personnel
- Going through and logging the Contributing Factors that led to the incident
- Answering any questions you've configured in Lessons Learned
- Reviewing completed/open Tasks, and creating any Follow-Ups as needed
- And then finally, publishing the retrospective and exporting it to PDF or other destinations
For a refresher on Retrospectives, visit Conducting Retrospectives.
5. Review your analytics
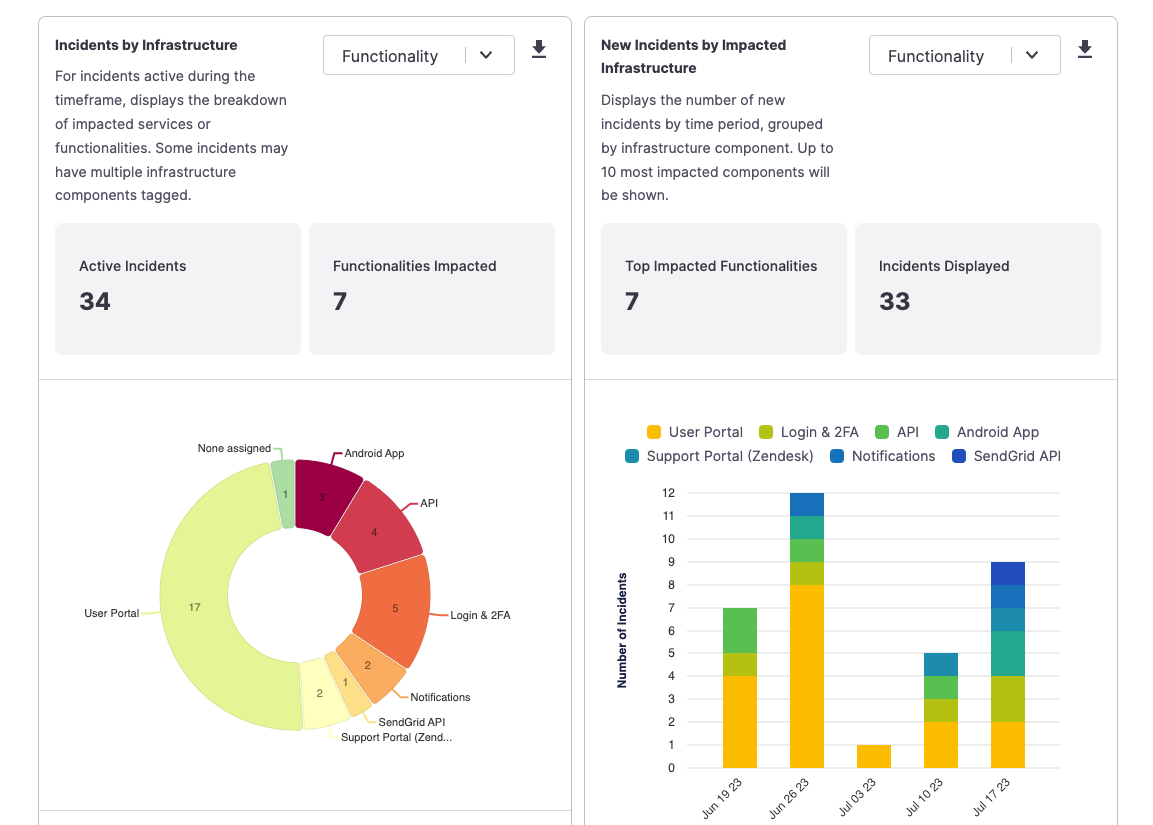
Once you've completed the retrospective, head over to the FireHydrant UI analytics section to see what metrics we track. For a refresher, see Analytics Basics.
Review the drill
The most critical questions are essentially byproducts of the default questions we include in the Retrospective.
- What went well?
- What were the best parts of running through the incident on FireHydrant?
- What did responders like or find a lot of value in?
- How can the team double down on these and ensure consistency and training for all responders?
- What could be improved?
- What were some areas where the process hiccuped?
- What did responders not like? Where could the team use more training?
- How can the team improve these pieces and revisit the improvements for feedback?
- Where did we get lucky?
- Was there anything that went well unintentionally?
- How can the team turn that into a regular process so that it's intentionally good next time?
- What were we wrong about?
- What assumptions were proven false?
- Were the bottlenecks what we thought they would be?
- Is there a better way to do things than how we want to do things?
By properly reviewing the outcomes of fire drills, just like with incidents, you can ensure your team has learned from the drill and will make improvements for next time and actual, real incidents.
We hope this guide has been helpful to you. As always, if you have questions, you may contact our support team or your account team if you are working with one. Happy firefighting!
Updated 11 months ago